MySQL UPSERT
MySQL UPSERT
UPSERT是数据库管理系统软件的核心功能之一,用于管理数据库。此操作允许DML用户向表中插入新纪录或更新现有数据。UPSERT由两个单词组成,分别是UPDATE和INSERT。前两个字母UP代表UPDATE,SERT代表INSERT。UPSERT是一个原子操作,意味着它是一步完成的操作。例如,如果记录是新的,则会触发一个INSERT命令。但是,如果它已经存在于表中,则此操作将执行一个UPDATE语句。
默认情况下,MySQL提供了ON DUPLICATE KEY UPDATE选项来完成INSERT操作,它可以实现这个任务。然而,它还包含其他一些语句来实现这个目标,比如INSERT IGNORE或REPLACE。我们将详细学习并查看所有这些解决方案。
MySQL UPSERT示例
我们可以通过以下三种方式执行MySQL UPSERT操作:
- 使用INSERT IGNORE进行UPSERT
- 使用REPLACE进行UPSERT
- 使用INSERT ON DUPLICATE KEY UPDATE进行UPSERT
使用INSERT IGNORE进行UPSERT
使用INSERT IGNORE语句可以在执行插入操作时忽略无效行的错误。例如,主键列不允许存储重复值。如果我们尝试插入一个具有与表中已存在的主键相同的新记录,就会出现错误。然而,如果我们使用INSERT IGNORE命令执行此操作,它将生成一个警告而不是错误。
语法
以下是在MySQL中使用INSERT IGNORE语句的语法:
INSERT IGNORE INTO table_name (column_names)
VALUES ( value_list), ( value_list) .....;
MySQL的INSERT IGNORE示例
让我们了解MySQL中INSERT IGNORE语句的工作原理。首先,我们需要使用以下语句创建一个名为 “Student” 的表:
CREATE TABLE Student (
Stud_ID int AUTO_INCREMENT PRIMARY KEY,
Name varchar(45) DEFAULT NULL,
Email varchar(45) NOT NULL UNIQUE,
City varchar(25) DEFAULT NULL
);
UNIQUE 约束条件确保我们不能将重复的值存入 email列 中。 接下来,需要将记录插入表中。 以下语句用于向表中添加数据:
INSERT INTO Student(Stud_ID, Name, Email, City)
VALUES (1,'Stephen', 'stephen@javatpoint.com', 'Texas'),
(2, 'Joseph', 'Joseph@javatpoint.com', 'Alaska'),
(3, 'Peter', 'Peter@javatpoint.com', 'California');
现在,我们可以通过使用 SELECT 语句来验证 insert 操作:
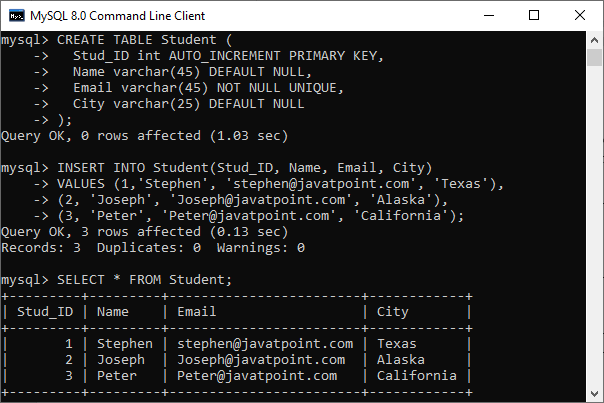
mysql> SELECT * FROM Student;
我们将获得以下输出,其中表格中有 三个 行:
现在,我们将执行以下语句将两条记录添加到表中:
INSERT INTO Student(Stud_ID, Name, Email, City)
VALUES (4,'Donald', 'donald@javatpoint.com', 'New York'),
(5, 'Joseph', 'Joseph@javatpoint.com', 'Chicago');
执行上述语句后,我们将看到以下错误: 错误 1062 (23000):键 ‘student.Email’ 中已存在重复条目 ‘ stash ‘, 这是因为该电子邮件违反了唯一约束。
但是,当我们使用 INSERT IGNORE 命令执行相同的语句时,我们没有收到任何错误。相反,我们只收到一个警告。
INSERT IGNORE INTO Student(Stud_ID, Name, Email, City)
VALUES (4,'Donald', 'donald@javatpoint.com', 'New York'),
(5, 'Joseph', 'Joseph@javatpoint.com', 'Chicago');
MySQL将产生一条消息:添加了一行,另一行被忽略。
1 row affected, 1 warning(s): 1062 Duplicate entry for key email.
Records: 2 Duplicates: 1 Warning: 1
通过 SHOW WARNINGS 命令,我们可以查看详细的警告信息:
因此,如果存在重复数据并且我们使用INSERT IGNORE语句,MySQL会发出警告而不是错误,并将剩余的记录添加到表中。
使用REPLACE进行UPSERT
在某些情况下,我们希望将现有记录更新到表中以保持其更新状态。如果我们使用标准的插入查询来实现这个目的,它会给出”Duplicate entry for PRIMARY KEY”错误。在这种情况下,我们将使用REPLACE语句来执行我们的任务。当我们使用REPLACE命令时,会发生两种可能的情况:
- 如果在现有数据行中找不到匹配值,则执行标准的INSERT语句。
- 如果旧记录与新记录匹配,replace命令将删除现有行,然后执行一个普通的INSERT语句将新记录添加到表中。
在REPLACE语句中,更新分为两个步骤。首先,它会删除现有记录,然后添加新更新的记录,类似于标准的INSERT命令。因此,我们可以说REPLACE语句执行了两个标准的功能,DELETE和INSERT。
MySQL中REPLACE语句的语法如下:
REPLACE [INTO] table_name(column_list)
VALUES(value_list);
示例
让我们通过一个真实的例子来理解它。在这里,我们将采用一个我们之前创建的 学生 表格,里面包含以下数据:
现在,我们将使用REPLACE语句来更新 id = 2的学生的城市 为新城市 Los Angeles 。为了做到这一点,请执行以下语句:
REPLACE INTO Student(Stud_ID, Name, Email, City)
VALUES(2, 'Joseph', 'joseph@javatpoint.com', 'Los Angeles');
成功执行后,我们将得到以下输出:
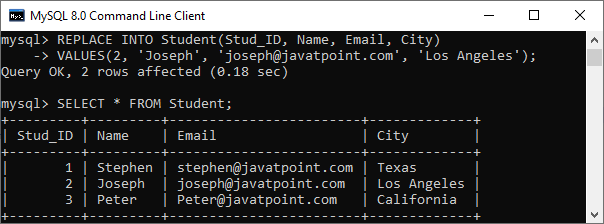
在上面的图像中,我们可以看到一个消息,上面写着 “2 row(s) affected” 尽管我们只更新了一行的值。这是因为REPLACE命令首先删除了记录,然后添加了新记录到表中。因此,消息显示”2 row(s) affected”。
使用INSERT ON DUPLICATE KEY UPDATE 进行UPSERT操作
到目前为止,我们已经看到了两种UPSERT命令,但它们都有一些限制。INSERT IGNORE语句只会忽略重复的错误,而不对表进行任何修改。而REPLACE方法会检测INSERT错误,但在添加新记录之前会删除该行。因此,我们仍然在寻找一种更精细的解决方案。
因此,我们采用了一种更精细的解决方案,即 INSERT ON DUPLICATE KEY UPDATE 语句。它是一种非破坏性的方法,意味着它不会删除重复的行。相反,当我们在SQL语句中指定了 ON DUPLICATE KEY UPDATE 子句,并且一行将导致在 UNIQUE 或 PRIMARY KEY 索引列中具有重复错误值时,会对现有行进行更新。
MySQL中的 Insert on Duplicate Key Update 语句的语法如下:
INSERT INTO table (column_names)
VALUES (data)
ON DUPLICATE KEY UPDATE
column1 = expression, column2 = expression...;
示例
让我们通过一个真实的示例来理解它。在这里,我们将采取一个先前创建的 学生 表格。现在,使用以下查询将一行添加到表中:
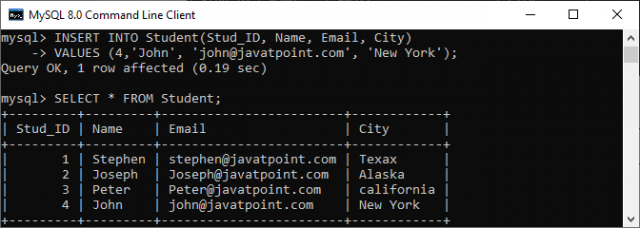
INSERT INTO Student(Stud_ID, Name, Email, City)
VALUES (4,'John', 'john@javatpoint.com', 'New York');
这个查询将会成功地向表中添加一条记录,因为它没有重复的值。
下一步,执行下面的MySQL UPSERT命令来更新重复记录在 Stud_ID 列中:
INSERT INTO Student(Stud_ID, Name, Email, City)
VALUES (4, 'John', 'john@javatpoint.com', 'New York')
ON DUPLICATE KEY UPDATE City = 'California';
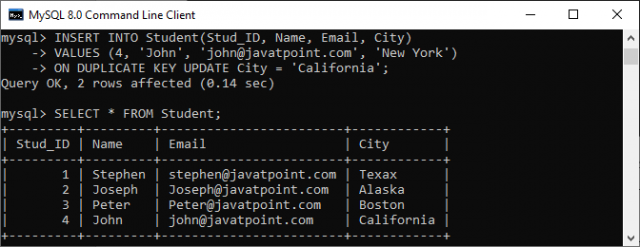
执行成功后,MySQL将显示以下消息:
Query OK, 2 rows affected.
在输出中,我们可以看到 行id = 4 已经存在。因此,查询只更新 城市纽约 为 加利福尼亚州 。
本文链接:http://so.lmcjl.com/news/15847/