MySQL 事务
MySQL 事务
MySQL中的事务是一组顺序的语句、查询或操作,如选择、插入、更新或删除,作为一个单一的工作单元来执行,可以提交或回滚。如果事务对数据库进行了多次修改,会发生两件事情:
- 当事务提交时,所有修改都成功。
- 当事务回滚时,所有修改都被撤销。
换句话说,如果在集合中没有完成每个操作,事务将无法成功。这意味着如果任何语句失败,事务操作将无法产生结果。
MySQL中的事务从第一个可执行的SQL语句开始,并在找到显式或隐含的提交或回滚时结束。它显式使用COMMIT或ROLLBACK语句,在使用DDL语句时隐含地使用。
让我们通过以下解释来理解事务的概念。
通过考虑一个 银行数据库 ,我们可以理解MySQL中的事务概念。假设银行客户想要将钱从一个账户转移到另一个账户。我们可以通过使用SQL语句来实现,将其分为以下步骤:
- 首先,需要检查第一个账户中所请求金额的可用性。
- 接下来,如果金额可用,就从第一个账户中扣除它。然后更新第一个账户。
- 最后,将金额存入第二个账户。然后更新第二个账户以完成交易。
- 如果上述任何一个过程失败,事务将回滚到其先前状态。
事务的特性
事务主要包含四个特性,这被称为 ACID 特性。现在,我们将详细讨论ACID特性。ACID特性代表:
- 原子性
- 一致性
- 隔离性
- 持久性
原子性: 这个特性确保事务单元中的所有语句或操作必须成功执行。否则,如果任何操作失败,整个事务将被中止,并且回滚到它们的先前状态。它包括以下特性:
- COMMIT语句。
- ROLLBACK语句。
- 自动提交设置。
- 从INFORMATION_SCHEMA表获取操作数据。
一致性: 这个特性确保只有在事务成功提交时,数据库才会改变状态。它还负责保护数据免受崩溃的影响。它包括以下特性:
- InnoDB的双写缓冲区。
- InnoDB崩溃恢复。
隔离性: 这个特性保证事务单元中的每个操作独立操作。它还确保语句对彼此透明。它包括以下特性:
- SET ISOLATION LEVEL语句。
- 自动提交设置。
- InnoDB锁的低级细节。
持久性: 这个特性保证已提交事务的结果即使在系统崩溃或失败的情况下也会永久存在。它包括以下特性:
- 存储设备中的写入缓冲区。
- 存储设备中的带电池缓存。
- 配置选项innodb_file_per_table。
- 配置选项innodb_flush_log_at_trx_commit。
- 配置选项sync_binlog。
MySQL事务语句
MySQL通过以下语句控制事务:
- MySQL提供了START TRANSACTION语句来开始事务。它还提供了”BEGIN”和”BEGIN WORK”作为START TRANSACTION的别名。
- 我们将使用COMMIT语句来提交当前事务。它允许数据库永久性地进行更改。
- 我们将使用ROLLBACK语句来回滚当前事务。它允许数据库取消所有更改并回到它们的先前状态。
- 我们将使用SET auto-commit语句来禁用/启用当前事务的自动提交模式。默认情况下,COMMIT语句会自动执行。因此,如果不想自动提交更改,请使用以下语句:
SET autocommit = 0;
OR,
SET autocommit = OFF:
再次,使用以下语句启用自动提交模式:
SET autocommit = 1;
OR,
SET autocommit = ON:
MySQL事务示例
假设我们有两个表格分别命名为 “employees” 和 “Orders” ,它们包含以下数据:
表格:employees
表格:订单
COMMIT示例
如果我们想使用事务,就需要将SQL语句分割成逻辑部分。然后,我们可以定义数据是提交还是回滚。
以下步骤介绍了如何创建一个事务:
- 使用START TRANSACTION语句开始事务。
- 然后,在员工中选择最大收入。
- 向员工表中添加一条新记录。
- 向订单表中添加一条新记录。
- 使用COMMIT语句完成事务。
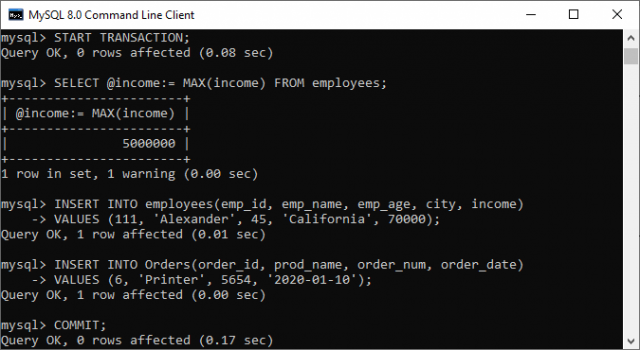
下面是执行上述操作的命令:
-- 1. Start a new transaction
START TRANSACTION;
-- 2. Get the highest income
SELECT @income:= MAX(income) FROM employees;
-- 3. Insert a new record into the employee table
INSERT INTO employees(emp_id, emp_name, emp_age, city, income)
VALUES (111, 'Alexander', 45, 'California', 70000);
-- 4. Insert a new record into the order table
INSERT INTO Orders(order_id, prod_name, order_num, order_date)
VALUES (6, 'Printer', 5654, '2020-01-10');
-- 5. Commit changes
COMMIT;
下方的图片更清楚地解释了这一点:
回滚示例
我们可以通过下面的示例理解回滚事务。首先,打开MySQL命令提示符并使用密码登录到数据库服务器。接下来,我们需要选择一个数据库。
假设我们的数据库包含“ 订单 ”表。现在,以下是执行回滚操作的脚本:
-- 1. Start a new transaction
START TRANSACTION;
-- 2. Delete data from the order table
DELETE FROM Orders;
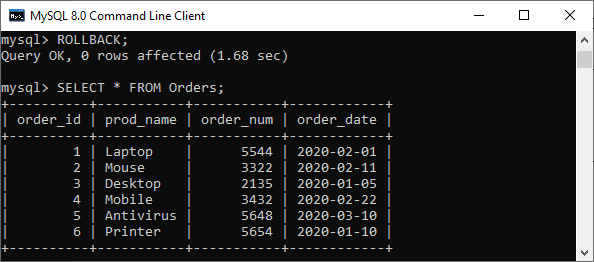
执行上述语句后,我们将获得以下输出,显示成功删除了表Orders中的所有记录。
现在,我们需要打开一个独立的MySQL数据库服务器会话,并执行以下语句来验证订单表中的数据:
SELECT * FROM Orders;
它将输出如下。
尽管我们在第一次会话中进行了更改,但我们仍然可以看到记录在表中可用。这是因为在第一次会话中未执行 COMMIT或ROLLBACK 语句之前,更改不是永久性的。
因此,如果我们想要使更改永久有效,请使用COMMIT语句。否则,请执行ROLLBACK语句以回滚第一次会话中的更改。
-- 3. Rollback changes
ROLLBACK;
-- 4. Verify the records in the first session
SELECT * FROM Orders;
在成功执行之后,它将产生以下结果,我们可以看到更改已被回滚。
在使用MySQL事务时不能回滚的语句。
MySQL事务不能回滚所有语句。例如,这些语句包括DDL(数据定义语言)命令,如创建、修改或删除数据库,以及创建、更新或删除表或存储过程。我们必须确保在设计事务时不包含这些语句。
保存点,回滚到保存点,释放保存点
保存点 语句在事务中创建一个带有 标识符 名称的特殊标记。它允许在保存点之后执行的所有语句都会被回滚。因此,事务会恢复到保存点所在的先前状态。如果在当前事务中设置了多个具有相同名称的保存点,则新的保存点负责回滚。
回滚到保存点 语句允许我们回滚到建立的给定保存点之前的所有事务,而不中止事务。
释放保存点 语句在当前事务中销毁指定的保存点,而不撤消保存点之后执行的查询的影响。在这些语句之后,不会发生回滚命令。如果保存点在事务中不存在,会产生错误。
以下是MySQL事务中上述语句的语法:
SAVEPOINT savepoint_name
ROLLBACK TO [SAVEPOINT] savepoint_name
RELEASE SAVEPOINT savepoint_name
示例
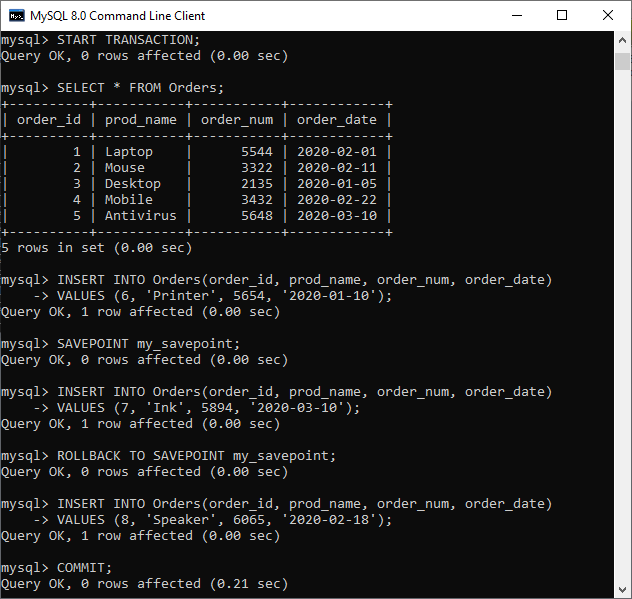
让我们通过一个例子来理解如何使用这些语句。在下面的例子中,我们将使用SAVEPOINT和ROLLBACK TO SAVEPOINT语句,这些语句解释了一个保存点如何确定可以回滚当前事务的哪些记录。
START TRANSACTION;
SELECT * FROM Orders;
INSERT INTO Orders(order_id, prod_name, order_num, order_date)
VALUES (6, 'Printer', 5654, '2020-01-10');
SAVEPOINT my_savepoint;
INSERT INTO Orders(order_id, prod_name, order_num, order_date)
VALUES (7, 'Ink', 5894, '2020-03-10');
ROLLBACK TO SAVEPOINT my_savepoint;
INSERT INTO Orders(order_id, prod_name, order_num, order_date)
VALUES (8, 'Speaker', 6065, '2020-02-18');
COMMIT;
在上面的步骤中,
- 首先,我们必须开始事务,然后显示在“Orders”表中可用的记录。
- 接下来,我们向表中插入了一条记录,然后创建了一个保存点标记。
- 然后,我们再次向表中插入了一条记录,然后使用ROLLBACK TO SAVEPOINT语句将保存点之后的更改取消。
- 再次,我们向表中插入了一条记录。
- 最后,执行COMMIT语句以永久保存更改。
下面的输出按顺序解释了上述步骤,帮助我们很容易地理解。
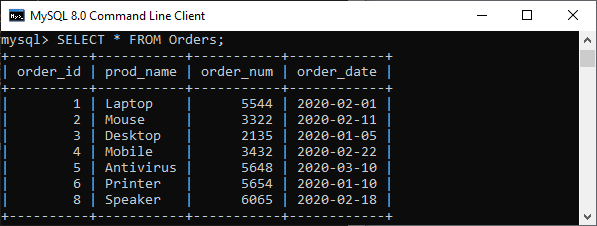
现在,我们将使用SELECT语句来验证上述操作。在输出中,我们可以看到 order_id=6 和 order_id=8 已成功添加,但是 order_id=7 没有被插入到表中。在保存点被建立后,它会回滚输入的值:
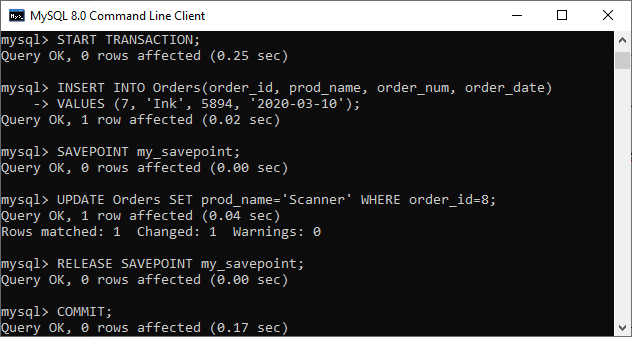
现在我们将进行另一个示例RELEASE SAVEPOINT,用于建立my_savepoint,并然后移除保存点。
START TRANSACTION;
INSERT INTO Orders(order_id, prod_name, order_num, order_date)
VALUES (7, 'Ink', 5894, '2020-03-10');
SAVEPOINT my_savepoint;
UPDATE Orders SET prod_name='Scanner' WHERE order_id=8;
RELEASE SAVEPOINT my_savepoint;
COMMIT;
在输出中,我们可以看到事务中的所有语句都成功执行。在这里,INSERT和UPDATE语句在提交时都会修改表。
本文链接:http://so.lmcjl.com/news/15853/